凯发官方首页-凯发娱乐登录 > 新闻中心 > 产品动态
车联网大数据平台架构设计-软硬件选型
1.软件选型建议
1.1 数据传输
处理并发链接的传统方式为:为每个链接创建一个线程并由该线程负责所有的数据处理业务逻辑。这种方式的好处在于代码简单明了,逻辑清晰。而由于操作系统的限制,每台服务器可以处理的线程数是有限的,因为线程对cpu的处理器的竞争将使系统整体性能下降。随着线程数变大,系统处理延时逐渐变大。此外,当某链接中没有数据传输时,线程不会被释放,浪费系统资源。为解决上述问题,可使用基于nio的技术。
1.1.1 netty
netty是当下十分流行的java nio框架。 netty框架中使用了两组线程:selectors与workers。其中selectors专门负责client端(列车车载设备)链接的建立并轮询监听哪个链接有数据传输的请求。针对某链接的数据传输请求,相关selector会任意挑选一个闲置的worker线程处理该请求。处理结束后,worker自动将状态置回‘空闲’以便再次被调用。两组线程的大线程数均需根据服务器cpu处理器核数进行配置。另外,netty内置了大量worker功能可以协助程序员轻松解决tcp粘包,二进制转消息等复杂问题。
1.1.2 ibm messagesight
messagesight是ibm的一款软硬一体的商业产品。其极限处理能力可达百万client并发,每秒可进行千万次消息处理。
1.2 数据预处理
1.2.1 流式数据处理
对于流式数据的处理不能用传统的方式先持久化存储再读取分析,因为大量的磁盘io操作将使数据处理时效性大打折扣。流式数据处理工具的基本原理为将数据切割成定长的窗口并对窗口内的数据在内存中快速完成处理。值得注意的是,数据分析的结论也可以被应用于流式数据处理的过程中,即可完成模式预判等功能还可以对数据分析的结论进行验证。
1.2.1.1 storm
storm是被广泛应用的开源产品中,其允许用户自定义数据处理的工作流(storm术语为topology),并部署在hadoop集群之上使之具备批量、交互式以及实时数据处理的能力。用户可使用任意变成语言定义工作流。
1.2.1.2 ibm streams
ibm的streams产品是性能非常可靠的流式数据处理工具。不同于其他基于java的开源项目,streams是用c 开发的,性能也远远高于其他流式数据处理的工具。另外ibm还提供了各种数据处理算法插件,包括:曲线拟合、傅立叶变换、gps距离等。
1.2.2 数据推送
为了实现推送技术,传统的技术是采用‘请求-响应式’轮询策略。轮询是在特定的的时间间隔(如每1秒),由浏览器对服务器发出请求,然后由服务器返回新数据给客户端的浏览器。这种传统的模式带来很明显的缺点,即浏览器需要不断的向服务器发出请求,然而http request 的header是非常长的,里面包含的数据可能只是一个很小的值,这样会占用很多的带宽和服务器资源。
面对这种状况,html5定义了websockets协议,能更好的节省服务器资源和带宽并达到实时通讯。应用websockets技术,服务器可以通过一个双工通道主动推送数据至客户端浏览器。
1.3 数据存储
1.3.1 车载终端数据
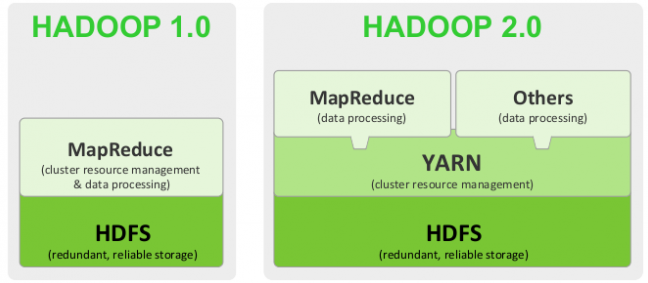
自2006年以来,基于google提出的mapreduce编程模型以及分布式文件系统的开源项目hadoop,得到了分布式计算领域的广泛关注,近年来更是几乎成为了大数据行业的标准框架。众多国际互联网公司如yahoo!、twitter、facebook、google、阿里巴巴等均开源发布了大量基于hadoop框架的软件,从而使得此框架拥有其他大数据工具所不具备的软件生态圈。
2013年底,hadoop 2 发布,新一代的计算框架yarn在兼容mapreduce之外,使得其他第三方计算工具可以更便捷的与hdfs整合。同时hdfs也增加了ha(高可用)等新功能。
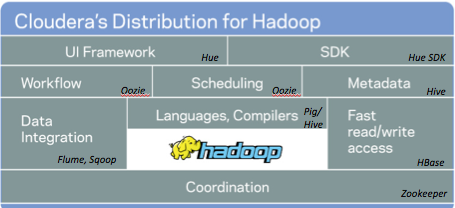
cloudera是一家美国的hadoop软件发行商,其cdh提供了企业级的凯发官方首页的服务支持,超过50%的hadoop开源项目贡献来自于cloudera的工程师。恒润科技目前使用的是cloudera的cdh5。
数据存入hdfs中时,hadoop会自动将数据切分为block并均匀分布的存储在集群的各个数据节点。读取数据时,往往通过map reduce的方式将数据汇总并提取。这种方式非常适用于对海量数据(eg. 100gb )进行检索或分析的场景。这是因为,首先海量数据很难用单机进行处理,因为大量数据需要先加载至内存;其次因为mapreduce(或基于yarn的其他计算方式)可以充分利用整个集群中的计算资源,任务的执行效率远远快于单机。
而对于交互应答及时性要求较高的应用场景,比如查看某列车某一时段的车速变化曲线(涉及数据量相对较小)。用户往往期望指定检索条件后可得到秒级的响应。但如果采用上述方式直接从hdfs取数据,整体集群任务派发与资源协调所需的时间将远大于数据处理与展示的时间。用户体验将会大幅下降,这种情况下一般会采用非结构型nosql数据库。hbase是hadoop生态圈中非结构型数据库的代表,其架构参考了google的bigtable设计。旨在为客户提供基于hdfs,支持快速写入与读取的数据库。
hbase的一个典型应用场景便是车载终端数据存储,车载终端数据的特点包括: 数据类型多样、数据具有时序性、车载终端有移动性以及数据粒度小。车载数据也符合上述特征,因此hbase相对于hdfs是一个更加合适的选择。然而,hbase表的设计对数据检索效率的影响可谓巨大,因此必须紧密结合应用场景、数据结构以及数据的元数据才能确保hbase的性能满足应用需求。
1.3.2 应用数据
应用数据一般则采用关系型数据库进行存储。常见的关系型数据库包括:mysql,sqlserver,oracle等。
1.4 数据分析
1.4.1 基础运算功能
大数据平台需根据数据类型的相应特点封装基础运算功能。例如,对于布尔量,需提供某段时间区间内,0、1变化的次数统计,0、1所占比例分布等功能;对递增量如列车里程,应提供某段时间区间内该信号的变化率。而这些功能在分布式环境下主要是通过mapreduce的思想实现。
mapreduce是hadoop的核心组件之一。 所有计算任务都被分解为两个过程:map与reduce。其中map过程的核心思想为‘移动计算优于移动数据’,即将计算任务mapper分发至数据所在计算节点。计算节点对本地数据进行计算并将计算结果记录在本地hdfs。reduce过程,则由reducer去各个计算节点收集mapper的中间计算结果再整理成结果。这一过程适合的场景是大批量数据运算,而针对交互性较强的应用,因整个计算过程涉及大量磁盘io操作,很难做到及时响应。为此hadoop软件生态圈对mapreduce过程进行了大量优化,而spark的出现则进一步颠覆了mapreduce的实现方式。
1.4.2 apache spark
spark将数据源封装为rdd(一种可伸缩的分布式数据结构)。针对rdd的mapreduce过程,将所有中间结果都保存在内存,而不需读写hdfs,从而提高计算任务的整体效率。除mapreduce外,spark还提供许多其他数据操作。自2014年起,spark已经成为apache开源社区中十分活跃的开源项目。
1.4.3 sql on hadoop
在传统关系型数据库中进行数据分析往往是依靠sql语言。对于不熟悉分布式编程的数据分析人员,sql on hadoop的出现无疑为他们提供了一种便捷而强大数据分析工具。为hbase提供sql操作的工具包括hive,impala与pheonix。其中hive与impala都是为hdfs而设计同时提供了对hbase的接口;pheonix则是专门为hbase设计的,底层实现完全依赖hbase 的原生接口。
1.4.4 机器学习算法
数据挖掘中常用的许多机器学习算法都是迭代式的,当数据分布在集群中,传统的单机算法实现将难以生效。apache mahout提供了多种机器学习算法基于mapreduce的实现,包括聚类、拟合、协同过滤等。spark也提供了mlib组件并以spark的方式对上述算法进行了实现。
1.4.5 bi
传统的的bi工具近年来也开始提供基于hadoop的数据计算接口,如matlab提供了mapreduce的接口(http://www.mathworks.com/discovery/matlab-mapreduce-hadoop.html)。而spss更是宣布除与hadoop集成之外,还将于2015年完成与spark的集成。值得注意的是,这些集成仅是底层实现的集成,即仍然要求数据分析人员具备mapreduce的编程思想并学习这些工具关于mapreduce的客户端接口。
1.4.6 工作流
oozie是hadoop生态圈中一款关于计算流程规划的工具。通过这款工具,开发人员可以将上述数据分析工具进行整合,以完成非常复杂的数据统计任务。然而oozie缺乏可视化的工具对工作流进行设计,且调试十分不便。
azkaban是由linkedin贡献的一款类似的开源工具并提供了用户友好的可视化界面。
1.4.7 数据可视化
由于前段的框架采用的是基于浏览器的b/s架构,因此数据的可视化可以依托于大量开源的javascript工具库,例如d3(https://github.com/mbostock/d3/wiki/gallery)、highcharts(http://www.highcharts.com/demo)以及baidu echarts(http://echarts.baidu.com/doc/example.html)。
以echarts为例,其提供的工具包括:折线(面积)图、 柱状(条形)图、 散点(气泡)图、 k线图、 饼(圆环)图、 雷达(面积)图、 和弦图、 力导向布局图、 地图、 仪表盘、 漏斗图。具体demo请参考上述链接。
2 硬件选型建议
2.1 服务器选型
2.1.1 配置
hadoop集群中datenode的推荐配置为:
• 12~24 块1~4tb 硬盘
• 2 ~8核 cpu, 频率2~2.5ghz
• 64-512gb 内存
• 10~100g以太网网口
namenode的推荐配置为:
• 4~6 块1tb 硬盘 (操作系统1块, 文件系统2块,zookeeper1块)
• 2 ~8核 cpu, 频率2~2.5ghz
• 64-128gb 内存
• 10~100g以太网网口
2.1.2 规模
车载终端数据进入hbase后,以hfile的形式存于hdfs。这意味着所有数据在整体集群中将会至少保存3个备份。规划集群规模时需考虑下列几个参数:
• 车载终端数量(车载数据采集设备)sensors
• 采集端口数量ports
• 采集频率 frequency
• 采集时间period
• 端口大小 size
• 备份数量 redundancy
由于hadoop集群支持动态扩展,因此策划时可先按需求搭建物理集群。