凯发官方首页-凯发娱乐登录 > 新闻中心 > 产品动态
使用 infosphere streams 进行海量数据实时处理
当前海量数据实时处理面临挑战
车联网是典型的大数据应用场景。以中等规模(百万辆车辆并行接入)的车联网系统为例,假设平均每辆车每秒通过无线通信实时上传的信号是200个,工作制式是7*13小时,3备份存储,则服务器所需提供的存储大小在一年内就轻松超过10pb。面对如此海量数据应用场合,传统的数据处理方式是“先存储后处理”,但是往往很多数据有实时处理的需求,比如实时监控,故障监测等,面对如此海量数据并行接入的情况,“传统”方式已无法满足海量数据实时处理的需求,流式计算应运而生。
流式计算
在“传统的”处理中,可以对历史数据运行分析查询:举例而言,针对车载终端实时传输的全球定位系统 (gps) 位置的数据集进行处理,计算某车辆一个月的里程。使用流计算,可以执行一种类似持续计算跑步距离的“持续查询”的过程,因为来自 gps 数据的位置信息不断在刷新。而在“传统的”数据处理方式而言,gps实时数据过来只能先存入数据库,然后等该月行程完成后,再对数据库历史数据进行查询计算得到当月里程。由于数据量比较大,这种类似离线分析的数据处理方式响应会非常慢,无法满足某些实时数据应用的场合。使用流式计算的好处是数据实时被处理,一方面可以满足海量数据实时分析的需求,另一方面针对海量价值比较低的数据进行预处理再存储,可以有效节省存储空间,有利于提高后续对数据处理的效率。流计算如下图所示:
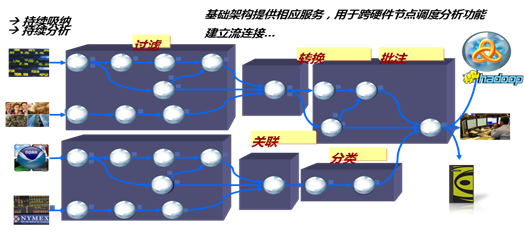
ibm infosphere streams为您提供海量数据实时分析平台
ibm infosphere streams是业内先进的流式计算软件,专门针对大数据的特性定制,完全能满足海量数据高并发,结构/半结构/非结构多形式数据场合实时数据处理需求。此外,streams也可以作为etl工具对原有数据库的历史数据进行处理,相比其它流式数据处理凯发娱乐登录的解决方案,streams的技术优势如下:
• streams是一种处理流数据的低延迟平台
♦ 能提供毫秒级,甚至微秒级端到端的延迟
• streams是一个可高度扩展的,用于实时分析的高性能平台
♦ 通过横向增加硬件可获得近线性的处理能力扩展
♦ 能支持高达125个节点的集群扩展
• streams是一个灵活的,动态的平台
♦ streams应用灵活部署,支持动态部署新的分析应用
♦ 支持机器学习,可以将现有的预测模型标记语言 (pmml) 模型重用到流数据上,对预测模型进行学习
• 提供丰富的工具箱,支持过滤、筛选、清洗等基本功能,支持用户java自定义工具箱
• 支持tcp/udp/file等数据接口,支持db2/informix/soliddb/oracle/sql server/mysql/netezza等数据库
streams研发项目是由美国政府和 ibm 于 2003 年协作启动,已由许多组织实施,在政府、电信、金融市场、能源、e-science 和医疗等行业构建各种各样的应用。
ibm infosphere streams 产品组件

图 3:infosphere streams 组件
• streams studio:一个基于 eclipse 3.6.2 的集成开发环境 (ide),用于迅速开发、测试和调试流应用和 streams live graph,以直观地显示在运行时集群上执行的作业和作业组件。
• streams 运行环境:一个服务器或服务器集群,集群大小没有限制。高可用性功能包括检测失败的流程元素、重新查找、重新启动和可选的重新存储状态的能力。
• 工具包、适配器和示例:
♦ 包含关系、文件、通信和实用程序操作符的标准工具包
♦ 包含 http、https、ftp、ftps、rss 和文件源操作符的 internet 工具包
♦ 包含 odbc 驱动程序和用于流扩充的高速soliddb驱动程序的数据库工具包
♦ 用于预测模型标记语言 (pmml) 评分的挖掘工具包
♦ 包含 websphere front office v3.0.2.1、financial information exchange (fix)、quantlib、library 函数的财务工具包,这些函数计算普通股期权衍生品值,比如 delta、theta、rho、vega 等
♦ 超过 50 个示例应用和流处理语言工件示例